Síntesis de proteínas: etapas y sus características
La síntesis de proteínas es un evento biológico que ocurre virtualmente en todos los seres vivos. Constantemente las células toman la información que está almacenada en el ADN y, gracias a la presencia de maquinaria especializada muy compleja, la transforman en moléculas de proteínas.
Sin embargo, el código de 4 letras encriptado en el ADN no se traduce directamente en proteínas. En el proceso se ve involucrada una molécula de ARN que funciona como intermediario, denominada ARN mensajero.
Cuando las células necesitan una proteína particular, la secuencia de nucleótidos de una porción adecuada en el ADN es copiada a ARN – en un proceso denominado transcripción – y este a su vez es traducido a la proteína en cuestión.
El flujo de información descrito (ADN a ARN mensajero y ARN mensaje a proteínas) ocurre desde seres muy simples como las bacterias hasta los humanos. Dicha serie de pasos se ha denominado el “dogma” central de la biología.
La maquinaria encargada de la síntesis proteínas son los ribosomas. Estas pequeñas estructuras celulares se encuentran en gran proporción en el citoplasma y anclado al retículo endoplasmático.
Índice del artículo
- 1 ¿Qué son las proteínas?
- 2 Etapas y características
- 2.1 Transcripción: de ADN a ARN mensajero
- 2.2 Splicing del ARN mensajero
- 2.3 Tipos de ARN
- 2.4 Traducción: de ARN mensajero a proteínas
- 2.5 El código genético
- 2.6 Acoplamiento del aminoácido al ARN de transferencia
- 2.7 El mensaje del ARN es decodificado por los ribosomas
- 2.8 Elongación de la cadena polipeptídica
- 2.9 Finalización de la traducción
- 3 Referencias
Las proteínas son macromoléculas formadas de aminoácidos. Estas constituyen casi el 80% del protoplasma de toda una célula deshidratado. Todas las proteínas que componen a un organismo se denominan “proteoma”.
Sus funcionados son múltiples y variadas, desde papeles estructurales (colágeno) hasta el transporte (hemoglobina), catalizadores de reacciones bioquímicas (enzimas), defensa contra patógenos (anticuerpos), entre otras.
Existen 20 tipos de aminoácidos naturales que se combinan mediante enlaces peptídicos para dar lugar a las proteínas. Cada aminoácido se caracteriza por poseer un grupo particular que le otorga propiedades químicas y físicas particulares.
La manera en que la célula logra interpretar el mensaje del ADN ocurre por medio de dos eventos fundamentales: la transcripción y la traducción. Muchas copias de ARN, que han sido copiadas de un mismo gen, son capaces de sintetizar un número importante de moléculas idénticas de proteínas.
Cada gen se transcribe y se traduce de manera diferencial, permitiéndole a la célula producir cantidades variadas de una amplia diversidad de proteínas. Este proceso implica diversas rutas de regulación celular, que generalmente incluyen el control en la producción de ARN.
El primer paso que la célula debe hacer para empezar la producción de proteínas es leer el mensaje escrito en la molécula de ADN. Esta molécula es universal y contiene toda la información necesaria para la construcción y el desarrollo de los seres orgánicos.
A continuación describiremos cómo ocurre la síntesis de proteínas, empezando dicho proceso de “lectura” del material genético y finalizaremos con la producción de proteínas per se.
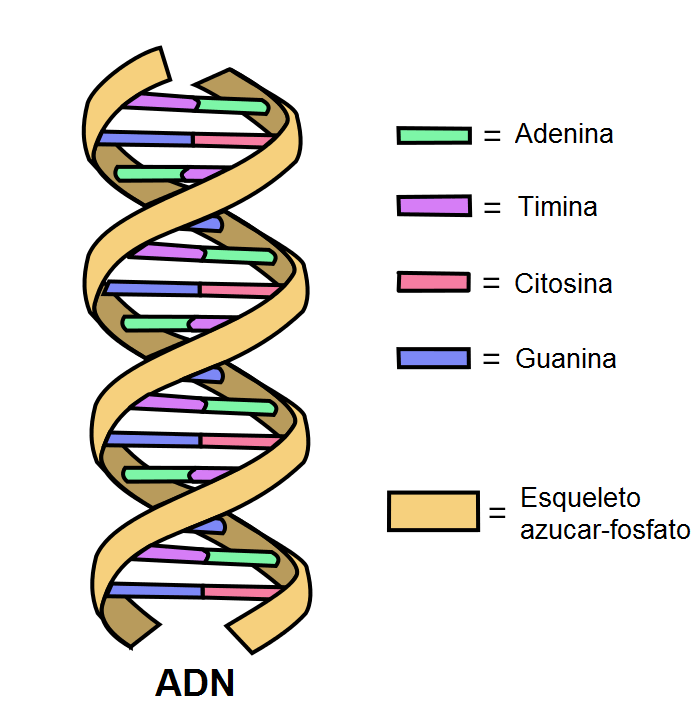
El mensaje en la doble hélice de ADN está escrito en un código de cuatro letras que corresponden a las bases adenina (A), guanina (G), citosina (C) y timina (T).
Esta secuencia de letras del ADN sirve de templado para construir una molécula equivalente de ARN.
Tanto el ADN como el ARN son polímeros lineales formados por nucleótidos. Sin embargo, difieren químicamente en dos aspectos fundamentales: los nucleótidos en el ARN son ribonucleótidos y en vez de la base timina, el ARN presenta el uracilo (U), que se aparea con la adenina.
El proceso de transcripción inicia con la apertura de la doble hélice en una región concreta. Una de las dos cadenas actúa como “molde” o templado para la síntesis del ARN. Se añadirán los nucleótidos siguiendo las reglas de apareamiento de bases, C con G y A con U.
La enzima principal que participa en la transcripción es la ARN polimerasa. Es la encargada de catalizar la formación de los enlaces fosfodiéster que unen los nucleótidos de la cadena. La cadena se va extendiendo en dirección 5´ a 3´.
El crecimiento de la molécula involucra distintas proteínas conocidas como “factores de elongación” que se encargan de mantener la unión de la polimerasa hasta el final del proceso.
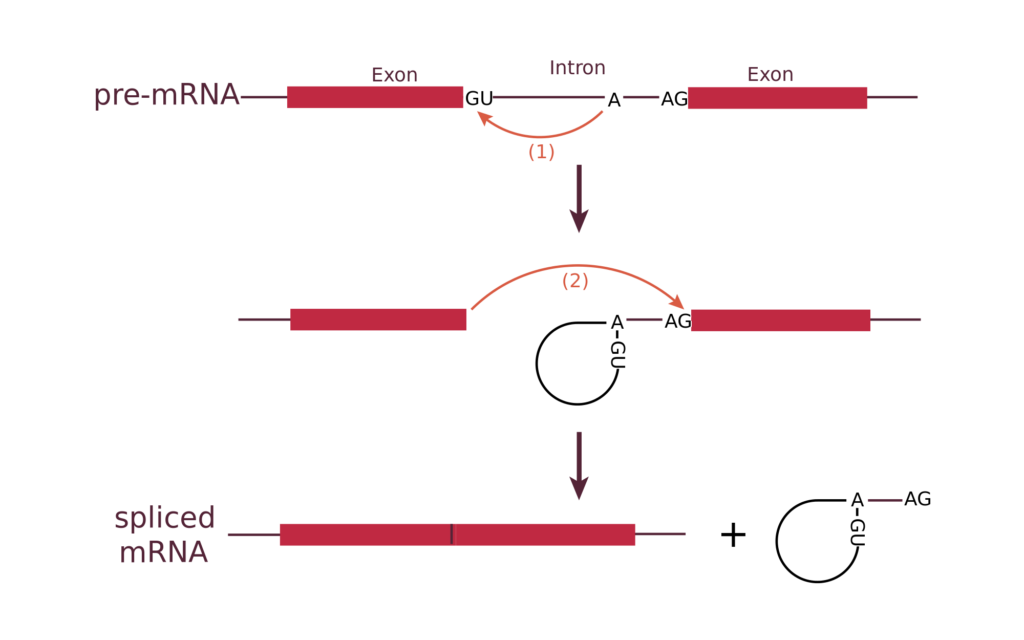
El splicing es un evento fundamental que consiste en la eliminación de los intrones de la molécula de mensajera, para arrojar una molécula construida exclusivamente por exones. El producto final es el ARN mensajero maduro. Físicamente, tiene lugar en el espliceosoma, una maquinaria compleja y dinámica.
Además del splicing, el ARN mensajero sufre codificaciones adicionales antes de ser traducido. Se añade una “capucha” cuya naturaleza química es un nucleótido modificado de guanina, y en el extremo 5´ y una cola de varias adeninas en el otro extremo.
En la célula, se producen diversos tipos de ARN. Algunos genes en la célula producen una molécula de ARN mensajero y esta se traduce a proteína – como veremos más adelante. No obstante, existen genes cuyo producto final es la molécula de ARN en sí.
Por ejemplo, en el genoma de la levadura, cerca del 10% de los genes de este hongo tienen como producto final moléculas de ARN. Es importante mencionarlos, ya que estas moléculas juegan un papel fundamental a la hora de la síntesis proteica.
– ARN ribosomal: el ARN ribosomal forma parte del corazón de los ribosomas, estructuras claves para la síntesis de las proteínas.
– ARN de transferencia: funciona como adaptador que selecciona un aminoácido específico y junto con el ribosoma, incorporan el residuo de aminoácido a la proteína. Cada aminoácido se relaciona con una molécula de ARN de transferencia.
En los eucariotas existen tres tipos de polimerasas que, aunque son estructuralmente muy similares entre sí, juegan papeles distintos.
La ARN polimerasa I y la III transcriben los genes que codifican para el ARN de trasferencia, ARN ribosomal y algunos ARN pequeños. La ARN polimerasa II se enfoca en la traducción de los genes que codifican para proteínas.
– ARN pequeños relacionados con la regulación: otros ARN de longitud corta participan en la regulación de la expresión génica. Entre ellos están los microARN y los ARN pequeños de interferencia.
Los microARN regulan la expresión mediante el bloqueo de un mensaje específico y los pequeños de interferencia apagan la expresión por medio de la degradación directa del mensajero. Del mismo modo, existen ARN pequeños nucleares que participan en el proceso de splicing del ARN mensajero.
Una vez que el ARN mensajero madura por medio del proceso de splicing yviaja desde el núcleo hasta el citoplasma celular, empieza la síntesis de proteínas. Esta exportación es mediada por el complejo del poro nuclear – una serie de canales acuosos localizados en la membrana del núcleo que conecta directamente el citoplasma y el nucleoplasma.
En la vida cotidiana, usamos el término “traducción” para referirnos a la conversión de palabras de un idioma a otro.
Por ejemplo, podemos traducir un libro de inglés a español. A nivel molecular, la traducción implica el cambio de lenguaje a ARN a proteína. Para ser más precisos, es el cambio de nucleótidos a aminoácidos. Pero, ¿cómo ocurre este cambio de dialecto?
La secuencia de nucleótidos de un gen puede transformarse a proteínas siguiendo las reglas establecidas por el código genético. Este fue descifrado a principios de los años 60.
Como el lector podrá deducir, la traducción no puede ser uno o uno, ya que existen sólo 4 nucleótidos y 20 aminoácidos. La lógica es la siguiente: la unión de tres nucleótidos se conoce como “tripletes” y se asocian a un aminoácido en particular.
Como pueden existir 64 posibles tripletes (4 x 4 x 4 = 64), el código genético es redundante. Es decir, un mismo aminoácido es codificado por más de un triplete.
La presencia del código genético es universal y es usado por todos los organismos vivos que hoy en día habitan la tierra. Este amplísimo uso es una de las homologías moleculares más sorprendente de la naturaleza.
Los codones o tripletes que se encuentran en la molécula de ARN mensajero no tienen la capacidad para reconocer directamente a los aminoácidos. En contraste, la traducción del ARN mensajero depende de una molécula que logre reconocer y unir al codón y al aminoácido. Esta molécula es el ARN de transferencia.
El ARN de trasferencia puede plegarse en una estructura tridimensional compleja que se asemeja a un trébol. En esta molécula existe una región denominada “anticodón”, formada por tres nucleótidos consecutivos que se aparean con los nucleótidos complementarios consecutivos de la cadena de ARN mensajero.
Como mencionamos en el apartado anterior, el código genético es redundante, por lo que algunos aminoácidos poseen más de un ARN de transferencia.
La detección y fusión del aminoácido correcto al ARN de trasferencia es un proceso mediado por una enzima llamada aminoacil – ARNt sintetasa. Esta enzima se encarga de acoplar ambas moléculas por medio de un enlace covalente.
Para formar una proteína, los aminoácidos se unen entre sí por medio de enlaces peptídicos. El proceso de lectura del ARN mensajero y unión de los aminoácidos específicos ocurre en los ribosomas.
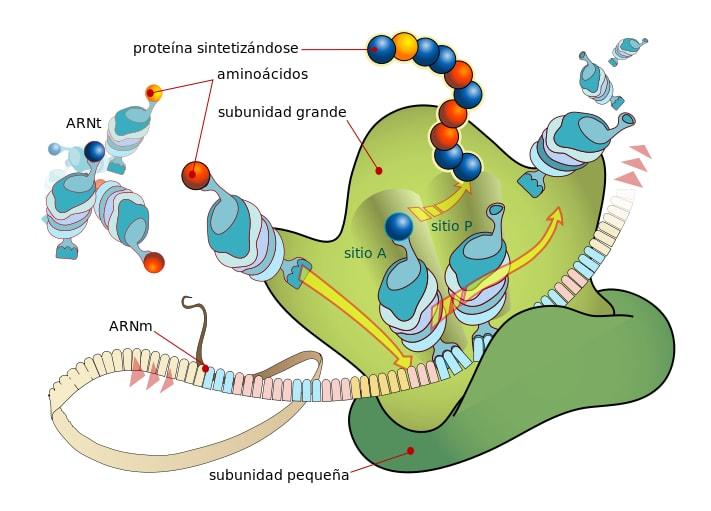
Los ribosomas son complejos catalíticos formados por más de 50 moléculas de proteínas y varios tipos de ARN ribosomal. En los organismos eucariotas, una célula promedio contiene en promedio millones de ribosomas en el ambiente citoplasmático.
Estructuralmente, un ribosoma está compuesto de una subunidad grande y una pequeña. La función de la porción pequeña es asegurar que el ARN de transferencia esté correctamente emparejado con el ARN mensajero, mientras que la subunidad grande cataliza la formación del enlace peptídico entre los aminoácidos.
Cuando el proceso de síntesis no se encuentra activo, las dos subunidades que forman los ribosomas se encuentran separadas. Al iniciar la síntesis, el ARN mensajero une ambas subunidades, generalmente cerca del extremo 5´.
En este proceso, la elongación de la cadena polipeptídica ocurre por la adición de un nuevo residuo de aminoácido en los siguientes pasos: unión del ARN de transferencia, formación del enlace peptídico, translocación de las subunidades. El resultado de este último paso es el movimiento del ribosoma completo y empieza un nuevo ciclo.
En los ribosomas se distinguen tres sitios: el sitio E, el P y el A (ver imagen principal). El proceso de elongación comienza cuando algunos aminoácidos ya han sido unidos covalentemente y hay una molécula de ARN de transferencia en el sitio P.
El ARN de transferencia que posee el próximo aminoácido a ser incorporado se une al sitio A por apareamiento de bases con el ARN mensajero. Luego, la porción carboxilo terminal del péptido es liberada del ARN de transferencia en el sitio P, por la ruptura de un enlace de alta energía entre el ARN de transferencia y el aminoácido que porta.
El aminoácido libre se une a la cadena, y se forma un nuevo enlace péptido. La reacción central de todo este proceso es mediada por la enzima peptidil transferasa, que se encuentra en la subunidad grande de los ribosomas. Así, el ribosoma se desplaza por el ARN mensajero, traduciendo el dialecto de aminoácidos a proteínas.
Como ocurre en la transcripción, durante la traducción de las proteínas también se ven involucrados factores de elongación. Estos elementos aumentan la rapidez y la eficacia del proceso.
El proceso de traducción concluye cuando el ribosoma encuentra a los codones de parada: UAA, UAG o UGA. Estos no son reconocidos por ningún ARN de transferencia y no unen ningún aminoácido.
En este momento, proteínas conocidas como factores de liberación se unen al ribosoma y produce la catálisis de una molécula de agua y no de un aminoácido. Esta reacción libera el extremo carboxilo terminal. Finalmente, la cadena de péptido es liberada al citoplasma celular.
- Berg JM, Tymoczko JL, Stryer L. (2002). Biochemistry. 5th edition. New York: W H Freeman.
- Curtis, H., & Schnek, A. (2006). Invitación a la Biología. Ed. Médica Panamericana.
- Darnell, J. E., Lodish, H. F., & Baltimore, D. (1990). Molecular cell biology. New York: Scientific American Books.
- Hall, J. E. (2015). Guyton and Hall textbook of medical physiology e-Book. Elsevier Health Sciences.
- Lewin, B. (1993). Genes. Volumen 1. Reverte.
- Lodish, H. (2005). Biología celular y molecular. Ed. Médica Panamericana.
- Ramakrishnan, V. (2002). Ribosome structure and the mechanism of translation. Cell, 108(4), 557-572.
- Tortora, G. J., Funke, B. R., & Case, C. L. (2007). Introducción a la microbiología. Ed. Médica Panamericana.
- Wilson, D. N., & Cate, J. H. D. (2012). The structure and function of the eukaryotic ribosome. Cold Spring Harbor perspectives in biology, 4(5), a011536.