¿Qué es un codón? (Genética)
¿Qué es un codón?
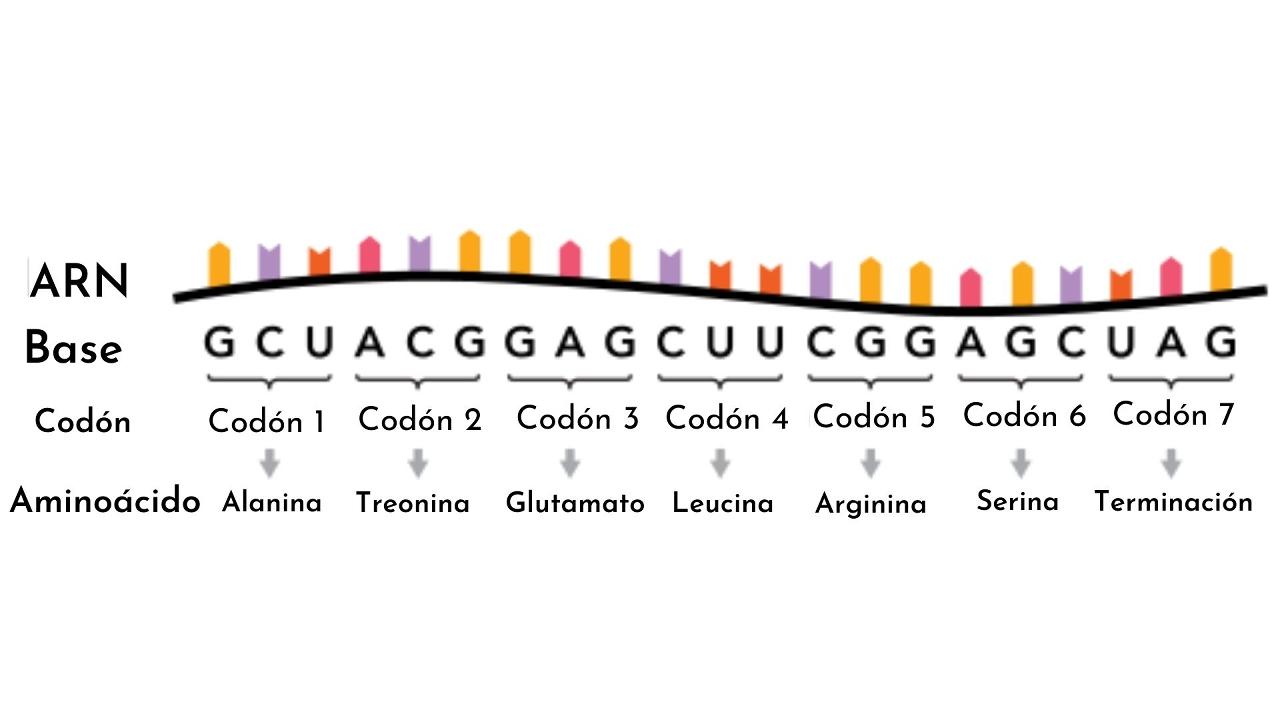
Un codón es cada una de las 64 combinaciones posibles de tres nucleótidos, basados en los cuatro que componen a los ácidos nucleicos. Es decir, a partir de combinaciones de los cuatro nucleótidos se construyen bloques de tres “letras”, o tripletes.
Estos son los desoxirribonucleótidos con las bases nitrogenadas adenina, guanina, timina y citosina en el ADN. En el ARN, son los ribonucleótidos con las bases nitrogenadas adenina, guanina, uracilo y citosina.
El concepto de codón se aplica solo para los genes que codifican para proteínas. El mensaje codificado en el ADN será leído en bloques de tres letras una vez que se procese la información de su mensajero.
El codón, en resumen, es la unidad básica de codificación para los genes que se traducen.
Codones y aminoácidos
Si para cada posición en palabras de tres letras contamos con cuatro posibilidades, el producto 4 X 4 X 4 nos proporciona 64 combinaciones posibles. Cada uno de estos codones corresponde a un aminoácido particular, excepto tres que funcionan como codones de fin de lectura.
La conversión de un mensaje codificado con bases nitrogenadas en un ácido nucleico a uno con aminoácidos en un péptido se denomina traducción. La molécula que moviliza el mensaje desde el ADN al sitio de la traducción se denomina ARN mensajero.
Un triplete de un ARN mensajero es un codón cuya traducción se llevará a cabo en los ribosomas. Las pequeñas moléculas adaptadoras que cambian el lenguaje de nucleótidos al de aminoácidos en los ribosomas son los ARN de transferencia.
Mensaje, mensajeros y traducción
Un mensaje que codifica para proteínas consiste en un arreglo lineal de nucleótidos que es múltiplo de tres. El mensaje es portado por un ARN que llamamos mensajero (ARNm).
En los organismos celulares todos los ARNm surgen por transcripción del gen codificado en su respectivo ADN. Es decir, los genes que codifican para proteínas están escritos en el ADN en el lenguaje de ADN.
Sin embargo, esto no significa que en el ADN se cumpla esta regla del tres de manera estricta. Al ser transcrito a partir del ADN, el mensaje es escrito ahora en lenguaje de ARN.
El ARNm consiste en una molécula con el mensaje del gen, flanqueado a ambos lados por regiones no codificantes. Ciertas modificaciones post-transcripcionales, como el splicing, por ejemplo, permiten generar un mensaje que cumple con la regla del tres.
Si en el ADN no parecía cumplirse esta regla del tres, el splicing la restituye.
El ARNm es transportado al sitio donde residen los ribosomas, y aquí el mensajero dirige la traducción del mensaje al lenguaje de proteínas.
En el caso más sencillo, la proteína (o péptido) tendrá un número de aminoácidos igual a un tercio de las letras del mensaje sin tres de ellas. Es decir, igual al número de codones del mensajero menos uno de terminación.
Mensaje genético
Un mensaje genético de un gen que codifica para proteínas comienza generalmente con un codón que se traduce como el aminoácido metionina (codón AUG, en el ARN).
Continúan luego un número característico de codones en una longitud y secuencia lineal específica, y termina en un codón de terminación. El codón de terminación puede ser uno de los codones ópalo (UGA), ámbar (UAG) u ocre (UAA).
Esto no tiene un equivalente en lenguaje de aminoácidos, y, por lo tanto, tampoco un ARN de transferencia correspondiente.
Sin embargo, en algunos organismos, el codón UGA permite la incorporación del aminoácido modificado selenocisteína. En otros, el codón UAG permite la incorporación del aminoácido pirrolisina.
EL ARN mensajero se acompleja con los ribosomas, y la iniciación de la traducción permite la incorporación de una metionina inicial. Si el proceso es exitoso, la proteína se irá elongando (alargando) en la medida en que cada ARNt vaya donando el aminoácido correspondiente guiado por el mensajero.
A llegar al codón de terminación, se detiene la incorporación de aminoácidos, concluye la traducción y se libera el péptido sintetizado.
Codones y anticodones
Aunque es una simplificación de un proceso bastante más complejo, la interacción codón-anticodón sustenta la hipótesis de la traducción por complementariedad.
Según esta, para cada codón en un mensajero, la interacción con un ARNt particular estará dictada por la complementariedad con las bases del anticodón.
El anticodón es la secuencia de tres nucleótidos (triplete) presente en la base circular de un ARNt típico. Cada ARNt específico se puede cargar con un aminoácido particular, que siempre será el mismo.
De esta manera, al reconocerse un anticodón, el mensajero le está indicando al ribosoma que debe aceptar el aminoácido que porta el ARNt para el cual es complementario en ese fragmento.
El ARNt actúa, pues, como un adaptador que permite que se verifique la traducción que lleva a cabo el ribosoma. Este adaptador, en pasos de lectura de codones de tres letras, permite la incorporación lineal de aminoácidos que constituye, finalmente, el mensaje traducido.
La degeneración del código genético
La correspondencia codón:aminoácido es conocida en biología como el código genético. Este código incluye también a los tres codones de terminación de la traducción.
Existen 20 aminoácidos esenciales, pero, a su vez, existen 64 codones disponibles para su reconversión. Si eliminamos los tres codones de terminación, nos quedan todavía 61 para codificar a los aminoácidos.
La metionina es codificada únicamente por el codón AUG, el cual es codón de inicio, pero también de este aminoácido particular en cualquier otra parte del mensaje (gen).
Esto nos lleva a que 19 aminoácidos sean codificados por los restantes 60 codones. Muchos aminoácidos son codificados por un único codón. Sin embargo, existen otros aminoácidos que son codificados por más de un codón. Esta falta de relación entre codón y aminoácido es lo que llamamos la degeneración del código genético.
Organelos
Finalmente, el código genético es parcialmente universal. En eucariotas existen otros organelos (derivados evolutivamente de bacterias) donde se verifica una traducción distinta a la que se verifica en el citoplasma.
Estos organelos con genoma (y traducción) propio son los cloroplastos y las mitocondrias. Los códigos genéticos de cloroplastos, mitocondrias, núcleos de eucariotas y nucleoides de bacteria no son exactamente idénticos.
Sin embargo, dentro de cada grupo sí es universal. Por ejemplo, un gen de plantas que se clone y traduzca en una célula animal dará origen a un péptido con la misma secuencia lineal de aminoácidos que tendría que haber sido traducido en la planta de origen.
Referencias
- Brooker, R. J. Genetics: Analysis and Principles. McGraw-Hill Higher, Education, New York.
- Griffiths, A. J. F., Wessler, R., Carroll, S. B., Doebley, J. An Introduction to Genetic Analysis. New York.
- Koonin, E. V., Novozhilov, A. S. Origin and evolution of the universal genetic code. Annual Review of Genetics.