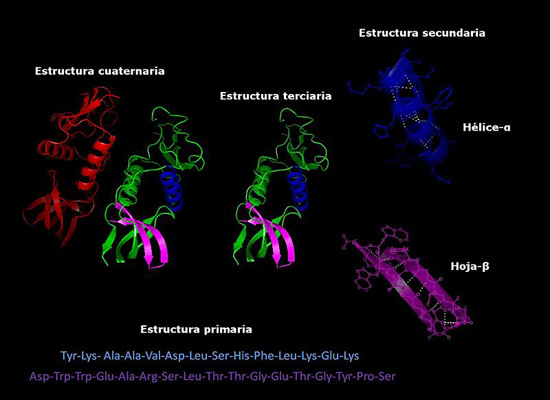
Estructura primaria de las proteínas: características
La estructura primariade las proteínas es el orden en el cual se disponen los aminoácidos del o de los polipéptidos que las conforman. Una proteína es un biopolímero formado por monómeros de α-aminoácidos unidos por medio de enlaces peptídicos. Cada proteína presenta una secuencia definida de estos aminoácidos.
Las proteínas desempeñan una enorme diversidad de funciones biológicas, entre ellas dar forma y mantener la integridad de las células mediante el citoesqueleto, defender el cuerpo de agentes extraños a través de los anticuerpos y catalizar las reacciones químicas del organismo por medio de las enzimas.
Actualmente, la determinación de la composición de las proteínas y del orden en que están dispuestos los aminoácidos (secuenciación) es más rápida que años atrás. Esta información es depositada en bases de datos electrónicas internacionales, a las cuales se pueden acceder vía internet (GenBank, PIR, entre otras).
Índice del artículo
- 1 Aminoácidos
- 2 Enlaces peptídicos
- 3 Secuencia de aminoácidos
- 4 Codificación de las proteínas
- 5 Referencias
Los aminoácidos son moléculas que contienen un grupo amino y un grupo ácido carboxílico. En el caso de los α-aminoácidos, estos presentan un átomo de carbono central (carbono α) al cual están unidos, tanto el grupo amino como el grupo carboxilo, además de un átomo de hidrógeno y un grupo R distintivo, el cual es llamado cadena lateral.
Debido a esta configuración del carbono α, los aminoácidos que se forman, conocidos como α-aminoácidos, son quirales. Se producen dos formas que son imágenes especulares una de otra y que son llamados enantiómeros L y D.
Todas las proteínas de los seres vivos están formadas por 20 α-aminoácidos de configuración L. Las cadenas laterales de estos 20 aminoácidos son distintas y presentan una gran diversidad de grupos químicos.
Básicamente, los α-aminoácidos pueden ser agrupados (arbitrariamente) dependiendo del tipo de cadena lateral de la siguientes manera.
En este grupo están contenidos, según algunos autores, la Glicina (Gli), Alanina (Ala), Valina (Val), Leucina (Leu) e Isoleucina (Ile). Otros autores incluyen también a la Metionina (Met) y a la Prolina (Pro).
Contiene la Serina (Ser), Cisteína (Cys), Treonina (Thr) y además Metionina. Según algunos autores, el grupo solo debería incluir a Ser y Thr.
Integrado únicamente por la Prolina, que, como ya fue señalado, es incluida por otros autores entre los aminoácidos alifáticos.
Fenilalanina (Phe), Tirosina (Tyr) y Triptofano (Trp).
Histidina (His), Lisina (Lys) y Arginina (Arg)
Contiene los ácidos Aspártico (Asp) y Glutámico (Glu) y además las amidas Aspargina (Asn) y Glutamina (Gln). Algunos autores separan este último grupo en dos; por un lado el de los aminoácidos ácidos (los dos primeros), y por otro los que contienen carboxilamida (los dos restantes).
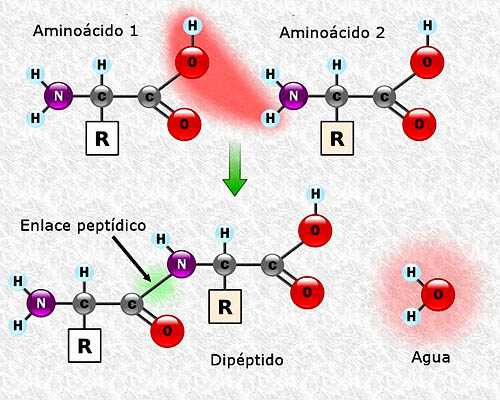
Los aminoácidos pueden unirse entre ellos por medio de enlaces peptídicos. Estos enlaces, también llamados enlaces amidas, se establecen entre el grupo α-amino de un aminoácido y el grupo α-carboxilo de otro. Esta unión se forma con la pérdida de una molécula de agua.
La unión entre dos aminoácidos resulta en la formación de un dipéptido, y si se añaden nuevos aminoácidos se podrían formar, secuencialmente, tripéptidos, tetrapéptidos, y así sucesivamente.
Los polipéptidos formados por un número pequeño de aminoácidos, reciben el nombre general de oligopéptidos, y si el número de aminoácidos es elevado, entonces se denominan polipéptidos.
Cada aminoácido que se adiciona a la cadena de polipéptidos libera una molécula de agua. La porción del aminoácido que ha perdido el H+ o el OH- durante la unión, recibe el nombre de resto aminoácido.
La mayoría de estas cadenas de oligopéptidos y polipéptidos van a presentar, en un extremo, un grupo amino-terminal (N-terminal), y en el otro un carboxilo terminal (C-terminal). Además de ello, pueden contener muchos grupos ionizables entre las cadenas laterales de los residuos aminoácidos que las conforman. Debido a ello, son considerados polianfolitos.
Cada proteína posee una secuencia determinada de sus residuos de aminoácidos. Este orden es el que se conoce como la estructura primaria de la proteína.
Cada proteína individual de cada organismo es específica de la especie. Es decir, la mioglobina de un ser humano es idéntica a la de otro ser humano, pero tiene pequeñas diferencias con las mioglobinas de otros mamíferos.
La cantidad y tipos de aminoácidos que contiene una proteína es tan importante como la ubicación de estos aminoácidos dentro de la cadena de polipéptidos. Para conocer las proteínas, los bioquímicos deben primero aislar y purificar cada proteína particular, luego hacer un análisis del contenido de aminoácidos, y por último determinar su secuencia.
Para aislar y purificar las proteínas existen diferentes métodos, entre los cuales se encuentran: la centrifugación, la cromatografía, la filtración en gel, la diálisis y la ultrafiltración, así como el empleo de las propiedades de solubilidad de la proteína en estudio.
La determinación de los aminoácidos presentes en las proteínas se realiza siguiendo tres pasos. El primero es romper los enlaces peptídicos por hidrólisis. Posteriormente son separados los distintos tipos de aminoácidos de la mezcla; y por último, se cuantifica cada uno de los tipos de aminoácidos obtenidos.
Para determinar la estructura primaria de la proteína, se pueden emplear distintos métodos; pero actualmente el más empleado es el método de Edman, que consiste, básicamente, en el marcaje y separación del aminoácido N-terminal del resto de la cadena en reiteradas ocasiones, e ir identificando cada aminoácido liberado individualmente.
La estructura primaria de las proteínas está codificada en los genes de los organismos. La información genética está contenida en el ADN, pero para su traducción a proteínas debe primero ser transcrita a moléculas de ARNm. Cada triplete de nucleótidos (codón) codifica un aminoácido.
Debido a que existen 64 posibles codones y solo 20 aminoácidos son empleados en la construcción de las proteínas, cada aminoácido puede ser codificado por más de un codón. Prácticamente todos los seres vivos emplean los mismos codones para codificar los mismos aminoácidos. Por ello, el código genético es considerado un lenguaje casi universal.
En este código, existen codones utilizados para iniciar y también detener la traducción del polipéptido. Los codones de finalización no codifican ningún aminoácido, sino que detienen la traducción en el C-terminal de la cadena, y están representados por los tripletes UAA, UAG y UGA.
Por otro lado, el codón AUG normalmente funciona como señal de comienzo y también codifica a la metionina.
Luego de la traducción, las proteínas pueden sufrir cierto procesamiento o modificación, como por ejemplo un acortamiento mediante fragmentación, para lograr su configuración definitiva.
- C.K. Mathews, K.E. van Holde & K.G. Ahern. 2002. Biochemestry. 3th edition. Benjamin / Cummings Publishing Company, Inc.
- Murray, P. Mayes, D.C. Granner & V.W. Rodwell. 1996. Harper’s Biochemestry. Appleton & Lange
- J.M. Berg, J.L. Tymoczko & L. Stryer (sf). Biochemestry. 5th edition. W. H. Freeman and Company.
- J. Koolman & K.-H. Roehm (2005). Color Atlas of Biochemistry. 2nd edition. Thieme.
- A. Lehninger (1978). Bioquímica. Ediciones Omega, S.A.
- L. Stryer (1995). Biochemestry. W.H. Freeman and Company, Nueva York.