Modelo relacional de base de datos: elementos, cómo hacerlo, ejemplo
El modelo relacionalde bases de datos es un método para estructurar datos utilizando relaciones, mediante estructuras en forma de cuadrícula, que consisten de columnas y filas. Es el principio conceptual de las bases de datos relacionales. Fue propuesto por Edgar F. Codd en 1969.
Desde entonces se ha convertido en el modelo de base de datos dominante para las aplicaciones comerciales, si se compara con otros modelos de bases de datos, como el jerárquico, de red y de objetos.
Codd no tenía idea de lo extremadamente vital e influyente que sería su trabajo como plataforma para las bases de datos relacionales. La mayoría de las personas está muy familiarizada con la expresión física de una relación en una base de datos: la tabla.
El modelo relacional se define como la base de datos que permite agrupar sus elementos de datos en una o más tablas independientes, que pueden relacionarse entre sí mediante el uso de campos comunes a cada tabla relacionada.
Índice del artículo
- 1 Manejo de base de datos
- 2 Características y elementos
- 3 ¿Cómo hacer un modelo relacional?
- 4 Ventajas
- 5 Desventajas
- 6 Ejemplo
- 7 Referencias
Una tabla de base de datos es similar a una hoja de cálculo. Sin embargo, las relaciones que se pueden crear entre las tablas permiten que una base de datos relacional almacene de manera eficiente una gran cantidad de datos, que se pueden recuperar con efectividad.
El propósito del modelo relacional es brindar un método declarativo para especificar los datos y las consultas: los usuarios declaran directamente qué información contiene la base de datos y qué información quieren de ella.
Por otro lado, dejan que el software del sistema de gestión de bases de datos se encargue de describir las estructuras de datos para su almacenamiento y el procedimiento de recuperación para responder las consultas.
La mayoría de las bases de datos relacionales usan el lenguaje SQL para la consulta y definición de los datos. Actualmente existen muchos sistemas de manejo de bases de datos relacionales o RDBMS (Relational Data Base Management System), como Oracle, IBM DB2 y Microsoft SQL Server.
– Todos los datos se representan conceptualmente como una disposición ordenada de datos en filas y columnas, llamada relación o tabla.
– Cada tabla debe tener un encabezado y un cuerpo. El encabezado es simplemente la lista de columnas. El cuerpo es el conjunto de datos que llena la tabla, organizado en filas.
– Todos los valores son escalares. Es decir, en cualquier posición dada de fila/columna en la tabla, hay solo un valor único.
La siguiente figura muestra una tabla con los nombres de sus elementos básicos, que conforman una estructura completa.

Tupla
Cada fila de datos es una tupla, conocida también como registro. Cada fila es una n-tupla, pero la “n-” generalmente se descarta.
Columna
Cada columna de una tupla se llama atributo o campo. La columna representa el conjunto de valores que puede tener un atributo específico.
Clave
Cada fila tiene una o más columnas que se denomina clave de la tabla. Este valor combinado es único para todas las filas de una tabla. Mediante esta clave se identificará cada tupla de forma unívoca. Es decir, la clave no puede estar duplicada. Se le llama clave primaria.
Por otro lado, una clave externa o secundaria es el campo de una tabla que se refiere a la clave primaria de alguna otra tabla. Se utiliza para referenciar a la tabla primaria.
Al diseñar el modelo relacional, se definen algunas condiciones que deben cumplirse en la base de datos, denominadas reglas de integridad.
Integridad de la clave
La clave primaria debe ser única para todas las tuplas y no puede tener el valor nulo (NULL). De lo contrario, no podrá identificar la fila de forma exclusiva.
Para una clave compuesta por varias columnas, ninguna de esas columnas puede contener NULL.
Integridad referencial
Cada valor de una clave externa debe coincidir con un valor de la clave primaria de la tabla referenciada o primaria.
En la tabla secundaria solo se podrá insertar una fila con una clave externa si ese valor existe en una tabla primaria.
Si el valor de la clave cambia en la tabla primaria, por actualizarse o eliminarse la fila, entonces todas las filas en las tablas secundarias con esta clave externa deben actualizarse o eliminarse en consecuencia.
Se deben recopilar los datos necesarios para almacenarlos en la base de datos. Estos datos se dividen en diferentes tablas.
Se debe elegir un tipo de datos apropiado para cada columna. Por ejemplo: números enteros, números de punto flotante, texto, fecha, etc.
Para cada tabla se debe elegir una columna (o pocas columnas) como clave primaria, que identificará de forma única cada fila de la tabla. La clave primaria también se utiliza para hacer referencia a otras tablas.
Una base de datos que consista de tablas independientes y no relacionadas tiene poco propósito.
El aspecto más crucial en el diseño de una base de datos relacional es identificar las relaciones entre las tablas. Los tipos de relación son:
Uno a muchos
En una base de datos “Listado de clases”, un maestro puede enseñar en cero o más clases, mientras que una clase es impartida por un solo maestro. Este tipo de relación se conoce como uno a muchos.
Esta relación no se puede representar en una sola tabla. En la base de datos “Listado de clases” se puede tener una tabla llamada Maestros, que almacena información sobre los maestros.
Para almacenar las clases impartidas por cada maestro, se podrían crear columnas adicionales, pero se enfrentaría un problema: cuántas columnas crear.
Por otro lado, si se tiene una tabla llamada Clases, que almacena información sobre una clase, se podrían crear columnas adicionales para almacenar la información sobre el maestro.
Sin embargo, como un maestro puede enseñar en muchas clases, sus datos se duplicarían en muchas filas de la tabla Clases.
Diseñar dos tablas
Por tanto, se necesitan diseñar dos tablas: una tabla Clases para almacenar información sobre las clases, con Clase_Id como clave principal, y una tabla Maestros para almacenar información sobre los maestros, con Maestro_Id como clave principal.
Luego se puede crear la relación uno a muchos almacenando la clave primaria de la tabla Maestro (Maestro_Id) en la tabla Clases, como se ilustra a continuación.
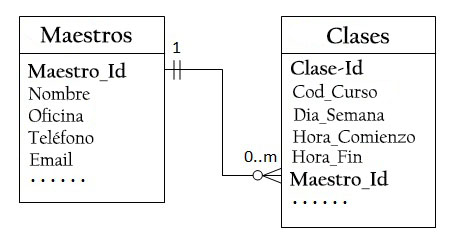
La columna Maestro_Id en la tabla Clases es conocida como clave externa o clave secundaria.
Para cada valor Maestro_Id en la tabla Maestro, puede haber cero o más filas en la tabla Clases. Para cada valor Clase_Id en la tabla Clases, hay solo una fila en la tabla Maestros.
Muchos a muchos
En una base de datos “Venta de productos”, el pedido de un cliente puede contener varios productos, y un producto puede aparecer en varios pedidos. Este tipo de relación se conoce como muchos a muchos.
Se puede comenzar la base de datos “Venta de productos” con dos tablas: Productos y Pedidos. La tabla Productos contiene información sobre los productos, con productoID como clave primaria.
Por otro lado, la tabla Pedidos contiene los pedidos del cliente, con pedidoID como clave primaria.
No se pueden almacenar los productos pedidos dentro de la tabla Pedidos, ya que no se sabe cuántas columnas reservar para los productos. Tampoco se pueden almacenar los pedidos en la tabla Productos por la misma razón.
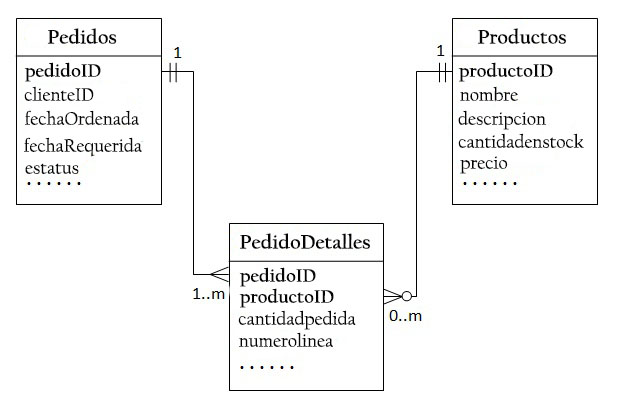
Para admitir una relación muchos a muchos, se necesita crear una tercera tabla, conocida como tabla de unión (PedidoDetalles), donde cada fila representa un elemento de un pedido particular.
Para la tabla PedidoDetalles, la clave primaria consta de dos columnas: pedidoID y productoID, identificando de forma única cada fila.
Las columnas pedidoID y productoID en la tabla PedidoDetalles se utilizan para referenciar a las tablas Pedidos y Productos. Por tanto, también son claves externas en la tabla PedidoDetalles.
Uno a uno
En la base de datos “Venta de productos”, un producto puede tener información opcional, como descripción adicional y su imagen. Mantenerla dentro de la tabla Productos generaría muchos espacios vacíos.
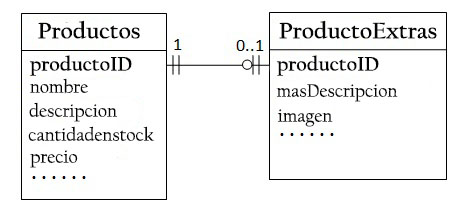
Por tanto, se puede crear otra tabla (ProductoExtras) para almacenar los datos opcionales. Solo se creará un registro para los productos con datos opcionales.
Las dos tablas, Productos y ProductoExtras, tienen una relación uno a uno. Para cada fila en la tabla Productos hay máximo una fila en la tabla ProductoExtras. Se debe usar el mismo productoID como clave principal para ambas tablas.
En el modelo relacional de base de datos, los cambios en la estructura de la base de datos no afectan el acceso a los datos.
Cuando es posible realizar cambios en la estructura de la base de datos sin afectar la capacidad del DBMS para acceder a los datos, se puede decir que se ha logrado la independencia estructural.
El modelo relacional de base de datos es aún más simple a nivel conceptual que el modelo jerárquico o el de red de base de datos.
Dado que el modelo relacional de base de datos libera al diseñador de los detalles del almacenamiento físico de los datos, los diseñadores pueden concentrarse en la vista lógica de la base de datos.
El modelo relacional de base de datos logra tanto la independencia de los datos como la independencia de la estructura, lo que hace que el diseño, el mantenimiento, la administración y el uso de la base de datos sean mucho más fáciles que los otros modelos.
La presencia de una capacidad de consulta muy potente, flexible y fácil de usar es una de las principales razones de la inmensa popularidad del modelo relacional de base de datos.
El lenguaje de consulta del modelo relacional de base de datos, llamado lenguaje de consulta estructurado o SQL, hace realidad las consultas ad-hoc. SQL es un lenguaje de cuarta generación (4GL).
Un 4GL permite al usuario especificar lo que se debe hacer, sin especificar cómo se debe hacer. Así, con SQL los usuarios pueden especificar qué información desean y dejar a la base de datos los detalles sobre cómo conseguir la información.
El modelo relacional de base de datos oculta las complejidades de su implementación y los detalles del almacenamiento físico de los datos de los usuarios.
Para hacer esto, los sistemas de bases de datos relacionales necesitan computadores con un hardware y dispositivos de almacenamiento de datos más potentes.
Por tanto, el RDBMS necesita máquinas potentes para que funcione sin problemas. Sin embargo, como la potencia de procesamiento de los computadores modernos está aumentando a un ritmo exponencial, la necesidad de más potencia de procesamiento en el escenario actual ya no es un problema muy grande.
La base de datos relacional es fácil de diseñar y usar. Los usuarios no necesitan conocer los detalles complejos del almacenamiento físico de los datos. No necesitan saber cómo se almacenan realmente los datos para acceder a ellos.
Esta facilidad de diseño y uso puede conducir al desarrollo e implementación de sistemas de gestión de bases de datos muy mal diseñados. Como la base de datos es eficiente, estas ineficiencias de diseño no saldrán a la luz cuando la base de datos esté diseñada y cuando haya solo una pequeña cantidad de datos.
A medida que la base de datos crezca, las bases de datos mal diseñadas ralentizarán el sistema y provocarán una degradación del rendimiento y corrupción de datos.
Como se ha dicho antes, los sistemas de bases de datos relacionales son fáciles de implementar y usar. Esto creará una situación en la que demasiadas personas o departamentos crearán sus propias bases de datos y aplicaciones.
Estas islas de información evitarán la integración de la información, que es esencial para el funcionamiento fluido y eficiente de la organización.
Estas bases de datos individuales también crearán problemas tales como inconsistencia de datos, duplicación de datos, redundancia de datos, etc.
Supongamos una base de datos que consta de las tablas Suplidores, Piezas y Envíos. La estructura de las tablas y algunos registros de muestra se exponen a continuación:
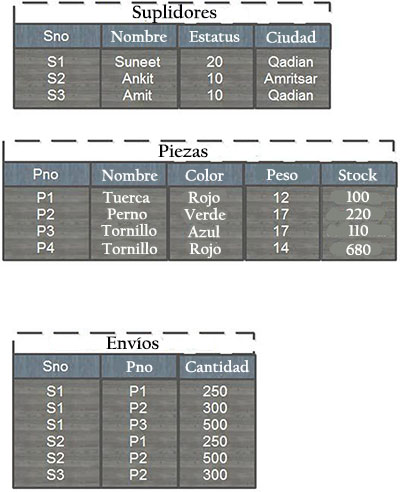
Cada fila en la tabla Suplidores se identifica mediante un número de suplidor (SNo) único, identificando de manera unívoca cada fila de la tabla. Igualmente, cada pieza tiene un número de pieza (PNo) único.
Además, no puede existir más de un envío para una combinación dada Suplidor / Pieza en la tabla Envíos, ya que esta combinación es la clave primaria de Envíos, que funge como tabla de unión, por ser una relación muchos a muchos.
La relación de las tablas Piezas y Envíos viene dada por tener en común el campo PNo (número de pieza) y la relación entre Suplidores y Envíos surge por tener en común el campo SNo (número de suplidor).
Analizando la tabla Envíos se puede obtener como información que se está enviando un total de 500 tuercas desde los suplidores Suneet y Ankit, 250 cada uno.
Igualmente, se enviaron 1.100 pernos en total desde tres suplidores diferentes. Se enviaron 500 tornillos azules desde el suplidor Suneet. No hay envíos de tornillos rojos.
- Wikipedia, the free encyclopedia (2019). Relational model. Tomado de: en.wikipedia.org.
- Techopedia (2019). Relational Model. Tomado de: techopedia.com.
- Dinesh Thakur (2019). Relational Model. Ecomputer Notes. Tomado de: ecomputernotes.com.
- Geeks for Geeks (2019). Relational Model. Tomado de: geeksforgeeks.org.
- Nanyang Technological University (2019). A Quick-Start Tutorial on Relational Database Design. Tomado de: ntu.edu.sg.
- Adrienne Watt (2019). Chapter 7 The Relational Data Model. BC Open Textbooks. Tomado de: opentextbc.ca.
- Toppr (2019). Relational Databases and Schemas. Tomado de: toppr.com.