Redes neuronales profundas: qué son y cómo funcionan
Las redes neuronales profundas son un concepto que constituye la principal arquitectura tecnológica usada en los modelos de Aprendizaje Profundo. Estas estructuras no se pueden comprender sin entender la idea general de las redes neuronales artificiales, fundamentales para la Inteligencia Artificial.
Las redes neuronales sirven para mil cosas: reconocer matrículas, canciones, caras, voz o, incluso, las frutas de nuestra cocina. Son una tecnología especialmente útil y que, pese a que hace relativamente poco que se han vuelto prácticas, van a constituir el futuro de la humanidad.
A continuación vamos a ver a fondo la idea de las redes neuronales artificiales y las profundas, entendiendo cómo funcionan, cómo son entrenadas y cómo se dan las interacciones entre las distintas neuronas que las constituyen.
- Artículo relacionado: "¿Qué es la Ciencia Cognitiva? Sus ideas básicas y fases de desarrollo"
¿Qué son las redes neuronales profundas y qué las caracteriza?
Las redes neuronales profundas son una de las arquitecturas tecnológicas más importantes usadas en la Deep Learning o Aprendizaje Profundo. Estas particulares redes artificiales han tenido un vertiginoso crecimiento en los últimos años porque constituyen un aspecto fundamental a la hora de reconocer todo tipo de patrones. La Inteligencia Artificial existe gracias al funcionamiento de estas particulares redes que, en esencia, vienen a ser una réplica de cómo funcionan nuestros cerebros, aunque de forma tecnológica y matemática.
Antes de abordar más a fondo qué son las redes neuronales profundas, primero tenemos que entender cómo funcionan las redes neuronales artificiales en general y para qué sirven. Las redes neuronales son una rama del “Machine Learning” que han tenido un enorme impacto en los últimos años, ayudando a programadores e informáticos a generar cosas como chatbots que, cuando hablamos con ellos, nos hacen pensar que estamos hablando con seres humanos reales.
Las redes neuronales artificiales también se han usado con coches que se conducen de manera automática, aplicaciones móviles que reconocen nuestra cara y la transforman en aquello que queramos y muchas más funciones. Su aplicabilidad es muy extensa, sirviendo como base de la Inteligencia Artificial moderna y teniendo un sinfín de usos provechosos para nuestro día a día.
Las redes neuronales artificiales
Imaginémonos que estamos en nuestra cocina y decidimos buscar una naranja, tarea muy sencilla. Sabemos identificar muy fácilmente una naranja y, también, sabemos diferenciarla de otras frutas que encontramos en la cocina, como lo son plátanos, manzanas y peras. ¿Cómo? Porque en nuestro cerebro tenemos muy asimiladas cuáles son las propiedades típicas de una naranja: su tamaño, su forma, el color que tiene, a qué huele… Son todo esto parámetros que usamos para encontrar una naranja.
Es una sencilla tarea para los humanos, pero... ¿la puede hacer un ordenador también? La respuesta es sí. En principio bastaría con definir esos mismos parámetros y asignarles un valor a un nodo o algo que bien podríamos llamar “neurona artificial”. A esa neurona le diríamos cómo son las naranjas, indicando su tamaño, el peso, la forma, el color o cualquier otro parámetro que atribuimos a esta fruta. Teniendo esta información es esperable que la neurona sepa identificar una naranja cuando se le presente una.
Si hemos escogido bien los parámetros le resultará fácil diferenciar entre naranjas y cosas que no son naranjas simplemente teniendo en cuenta esas características. Cuando se le presente una imagen de una fruta cualquiera, esa neurona buscará las características asociadas con la naranja y decidirá si incluirla en la categoría “naranja” o en la categoría “otras frutas”. En términos estadísticos, sería encontrar una región en un gráfico de parámetros que se corresponda a lo que se está buscando, una región que englobaría a todas las piezas de fruta que comparten tamaño, forma, color, peso y aroma que las naranjas.
De primeras todo esto suena muy fácil de codificar, y de hecho lo es. Funciona muy bien para diferenciar una naranja de un plátano o de una manzana, puesto que tienen colores y formas distintas. Sin embargo, ¿qué pasa si le presentamos un pomelo? ¿y una mandarina muy grande? Son frutas que perfectamente pueden confundirse con una naranja. ¿Será capaz la neurona artificial de diferenciar por sí sola entre naranjas y pomelos? La respuesta es no, y de hecho probablemente se piense que son lo mismo.
El problema de usar solamente una capa de neuronas artificiales, o lo que es lo mismo, solamente usar neuronas simples de primeras, es que generan las fronteras de decisión muy poco precisas cuando se le presenta algo que tiene muchas características en común con aquello que debería saber reconocer, pero que en realidad no lo es. Si le presentamos algo que se parece a una naranja, como lo es un pomelo, aunque no sea esa fruta lo va a identificar como tal.
Estas fronteras de decisión si son representadas en forma de gráfico van a ser siempre lineales. Usando una sola neurona artificial, es decir, un solo nodo que tiene integrados unos parámetros concretos pero que no puede aprender más allá de ellos, se obtendrán unas fronteras de decisión muy difusas. Su principal limitación es que usa dos métodos estadísticos, en concreto la regresión multiclase y la regresión logística, lo cual hace que ante la duda incluya algo que no es aquello que esperábamos que identificara.
Si tuviéramos que dividir todas las frutas en “naranjas” y “no naranjas”, usando solo una neurona está claro que los plátanos, las peras, las manzanas, las sandías y cualquier fruta que no se corresponde en tamaño, color, forma, aroma y demás con las naranjas las pondría en la categoría “no naranjas”. Sin embargo, los pomelos y las mandarinas las metería en la categoría “naranjas”, haciendo mal el trabajo para la que ha sido diseñada.
Y cuando hablamos de naranjas y pomelos bien podríamos hablar de perros y lobos, gallinas y pollos, libros y cuadernos… Todas estas situaciones son casos en los que no bastaría con una simple serie de “ifs...” (“si...”) para discernir claramente entre uno y otro. Es necesario un sistema más complejo, no lineal, que sea más preciso a la hora de diferenciar entre diferentes elementos. Algo que tenga en cuenta que entre lo parecido pueden haber diferencias. Es aquí donde entran las redes neuronales.
Más capas, más similar al cerebro humano
Las redes neuronales artificiales, como su propio nombre indica, son modelos artificiales computacionales inspirados en las propias redes neuronales del cerebro humano, redes que de hecho imitan el funcionamiento de este órgano biológico. Este sistema está inspirado en el funcionamiento neuronal y tiene como aplicación principal el reconocimiento de patrones de todo tipo: identificación facial, reconocimiento de voz, de huella dactilar, letra manuscrita, matrículas… El reconocimiento de patrones sirve para prácticamente todo.
Al haber distintas neuronas, los parámetros que se aplican son varios y se obtiene un grado de precisión mayor. Estas redes neuronales son sistemas que nos permiten separar los elementos en categorías cuando la diferencia puede ser sutil, separándolos de una manera no lineal, algo que sería imposible de hacer de otra manera.
Con un solo nodo, con una sola neurona, lo que se hace a la hora de manejar la información es una regresión multiclase. Al agregar más neuronas, como cada una de ellas tiene una función de activación no lineal propia que, traducido en un lenguaje más simple, hace que tengan unas fronteras de decisión que son más precisas, siendo gráficamente representadas de forma curva y teniendo en cuenta más características a la hora de diferenciar entre “naranjas” y “no naranjas”, por seguir con ese ejemplo.
La curvatura de esas fronteras de decisión va a depender directamente de cuántas capas de neuronas vayamos agregando a nuestra red neuronal. Esas capas de neuronas, que hacen que el sistema se vuelva más complejo y que tenga una precisión mayor son, en efecto, las redes neuronales profundas. En principio, cuantas más capas tengamos de redes neuronales profundas, más precisión y semejanza tendrá el programa en comparación con el cerebro humano.
En resumidas cuentas, las redes neuronales no son más que un sistema inteligente que permite tomar decisiones más precisas, de forma muy similar a cómo lo hacemos los seres humanos. Los seres humanos nos basamos en la experiencia, aprendiendo de nuestro entorno. Por ejemplo, volviendo al caso de la naranja y el pomelo, si nunca hemos visto uno, perfectamente lo confundiremos por una naranja. Cuando nos hayamos familiarizado con él será entonces cuando ya lo sepamos identificar y diferenciarlo de las naranjas.
Lo primero que se hace es darle unos parámetros a las redes neuronales para que sepan cómo es aquello que queremos que aprenda a identificar. Luego viene la fase de aprendizaje o entrenamiento, para que sea cada vez más precisa y vaya progresivamente teniendo un margen de error más reducido. Este es el momento en el que le presentaríamos a nuestra red neuronal una naranja y otras frutas. En la fase de entrenamiento se le darán casos en los que sí son naranjas y casos en los que no son naranjas, mirando si ha acertado en su respuesta y diciéndole la respuesta correcta.
Intentaremos que los intentos sean numerosos y lo más cercanos posibles a la realidad. De esta forma estamos ayudando a la red neuronal a operar para cuando lleguen casos reales y sepa discriminar adecuadamente, de la misma manera que lo haría un ser humano en la vida real. Si el entrenamiento ha sido adecuado, habiendo escogido unos buenos parámetros de reconocimiento y se han clasificado bien, la red neuronal va a tener una tasa de éxito de reconocimiento de patrones muy alta.
- Quizás te interese: "¿Cómo funcionan las neuronas?"
¿Cómo son y cómo funcionan exactamente?
Ahora que hemos visto la idea general de lo que son las redes neuronales y vamos a entender más a fondo cómo son y cómo funcionan estos emuladores de las neuronas del cerebro humano y dónde qué pintan las redes neuronales profundas en todo este proceso.
Imaginemos que tenemos la siguiente red neuronal: tenemos tres capas de neuronas artificiales. Pongamos que la primera capa tiene 4 neuronas o nodos, la segunda 3 y la última tiene solo 2. Todo esto es un ejemplo de red neuronal artificial, bastante sencilla de comprender.
La primera capa es la que recibe los datos, es decir, la información que bien puede venir en forma de sonido, imagen, aromas, impulsos eléctricos… Esta primera capa es la capa de entrada, y se encarga de recibir todos los datos para poder después mandarlos a las siguientes capas. Durante el entrenamiento de nuestra red neuronal será esta la capa con la que primero vamos a trabajar, dándole datos que usaremos para ver cómo de bien se le da realizar predicciones o identificar la información que se le da.
La segunda capa de nuestro hipotético modelo es la capa oculta, que se encuentra bien en medio de la primera y la última capa, como si nuestra red neuronal fuera un sándwich. En este ejemplo que damos solo tenemos una capa oculta, pero bien podrían haber tantas como quisiéramos. Podríamos hablar de 50, de 100, de 1000 o incluso de 50.000 capas. En esencia, estas capas ocultas son la parte de la red neuronal que denominaríamos red neuronal profunda. Cuanta mayor profundidad haya, más compleja es la red neuronal.
Por último tenemos la tercera capa de nuestro ejemplo que es la capa de salida. Esta capa, como bien indica su nombre, se encarga de recibir información de las capas anteriores, tomando una decisión y dándonos una respuesta o resultado.
En la red neuronal cada neurona artificial está conectada a todas las siguientes. En nuestro ejemplo, donde hemos comentado que tenemos tres capas de 4, 3 y 2 neuronas, las 4 de la capa de entrada están conectadas con las 3 de la capa oculta, y las 3 de la capa oculta con las 2 de la de salida, dándonos un total de 18 conexiones.
Todas estas neuronas están conectadas con las de la capa siguiente, enviando la información dirección entrada->oculta->salida. Si hubieran más capas ocultas hablaríamos de mayor cantidad de conexiones, enviándose la información de capa oculta a capa oculta hasta llegar a la capa de salida. La capa de salida, una vez haya recibido la información, lo que hará será darnos un resultado en base a la información que ha recibido y su forma de procesarla.
Cuando estamos entrenando nuestro algoritmo, es decir, nuestra red neuronal, este proceso que acabamos de explicar se va a hacer muchas veces. Le vamos a entregar unos datos a la red, vamos a ver qué nos da el resultado y vamos a analizarlo y compararlo con aquello que esperábamos que nos diera el resultado. Si hay mucha diferencia entre lo esperado y lo obtenido significa que hay un elevado margen de error y que, por lo tanto, es necesario hacer unas cuantas modificaciones.
¿Cómo funcionan las neuronas artificiales?
Ahora vamos a entender el funcionamiento individual de las neuronas que trabajan dentro de una red neuronal. La neurona recibe una entrada de información, procedente de la neurona anterior. Pongamos que esta neurona recibe tres entradas de información, cada una de ellas procedentes de las tres neuronas de la capa anterior. A su vez, esta neurona genera salidas, en este caso pongamos que solo está conectada a una neurona de la siguiente capa.
Cada conexión que tiene esta neurona con las tres neuronas de la capa anterior trae un valor “x”, el cual es el valor que nos está mandando la neurona anterior; y tiene también un valor “w”, que es el peso que tiene esta conexión. El peso es un valor el cual nos ayuda a darle mayor importancia a una conexión sobre otras. En resumidas cuentas, cada conexión con las neuronas anteriores tiene un valor “x” y uno “w”, que se multiplican (x·w).
También vamos a tener un valor llamado “bias” o sesgo representado con “b” el cual es el número de error el cual fomenta que ciertas neuronas se activen con mayor facilidad que las otras. Además, contamos con una función de activación dentro de la neurona, que es lo que hace que su grado de clasificación de diferentes elementos (p. ej., naranjas) no sea lineal. Por si sola cada neurona tiene unos parámetros distintos a tener en cuenta, lo cual hace que todo el sistema, esto es la red neuronal, clasifique de una forma no lineal.
¿Cómo sabe la neurona si se tiene que activar o no? es decir ¿cuando sabe si tiene que mandar información a la siguiente capa? Pues bien, esta decisión se rige por la siguiente ecuación:
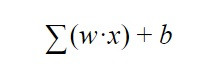
Esta fórmula viene a significar que se tiene que hacer el sumatorio de todos los pesos “w”multiplicados por todos los valores de “x” que está recibiendo la neurona procedentes de la capa anterior. Añadido a esto, se le suma el sesgo “b”.
El resultado de esta ecuación se manda a una función de activación, la cual es simplemente una función que nos dice que, si el resultado de esta ecuación es mayor a un determinado número, la neurona va a mandar señal a la siguiente capa y, en caso de que sea menor, entonces no va a mandarla. Entonces, así es como una neurona artificial decide si manda o no la información a las neuronas de la siguiente capa por medio de una salida que la denominaremos “y”, salida que, a su vez, es la entrada “x” de la siguiente neurona.
¿Y cómo se entrena toda una red?
Lo primero que se hace es entregarle datos a la primera capa, tal y como hemos comentado anteriormente. Esta capa va a mandar información a las siguientes capas, las cuales son las capas ocultas o la red neuronal profunda. Las neuronas de estas capas van a activarse o no en función de la información recibida. Finalmente, la capa de salida nos va a dar un resultado, el cual nosotros vamos a comparar con aquel valor que estábamos esperando para ver si la red neuronal ha aprendido bien lo que tiene que hacer.
Si no aprendió bien entonces realizaremos otra interacción, es decir, le presentaremos de nuevo información y veremos cómo se comporta la red neuronal. En función de los resultados obtenidos se van a ajustar los valores “b”, es decir, el sesgo de cada neurona, y los “w”, esto es el peso de cada conexión con cada neurona para reducir el error. Para saber cómo de grande es ese error vamos a usar otra ecuación, que es la siguiente:
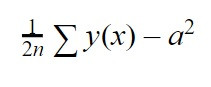
Esta ecuación es el error cuadrático medio. Vamos a hacer el sumatorio de y(x) que es el valor que nos dio nuestra red en la interacción menos “a”, que es el valor que estábamos esperando que nos diera, elevada al cuadrado. Por último, este sumatorio lo vamos a multiplicar por 1/2n, siendo esa “n” el número de interacciones que hemos mandado entrenar nuestra red neuronal.
Por ejemplo, imaginémonos que tenemos los siguientes valores

La primera columna “y(x)” representa que es lo que nos ha dado nuestra red en cada una de las cuatro interacciones que hemos hecho probándola. Los valores que hemos obtenido, como se puede ver, no se corresponden con los de la segunda columna “a”, que son los valores deseados para cada una de las interacciones probadas. La última columna representa el error de cada interacción.
Aplicando la fórmula anteriormente mencionada y usando estos datos aquí, teniendo en cuenta que en este caso n = 4 (4 interacciones) nos da un valor de 3,87 que es el error cuadrático medio que tiene nuestra red neuronal en estos momentos. Conocido el error lo que tenemos que hacer ahora es, como hemos comentado antes, cambiar el sesgo y los pesos de cada una de las neuronas y sus interacciones con la intención de que de esta forma el error se reduzca.
Llegados a este punto los ingenieros e informáticos aplican un algoritmo llamado gradiente descendiente con el cual pueden obtener valores para ir probando y modificando el sesgo y el peso de cada neurona artificial para que, de esta forma, se vaya obteniendo un error cada vez más bajo, acercándose a la predicción o resultado deseado. Es cuestión de ir probando y que, cuantas más interacciones se hagan, más entrenamiento habrá y más aprenderá la red.
Una vez la red neuronal está adecuadamente entrenada será cuando nos dará predicciones e identificaciones precisas y fiables. Llegados a este punto vamos a tener una red que va a tener en cada una de sus neuronas un valor de peso definido, con un sesgo controlado y con una capacidad de decisión que hará que el sistema funcione.
Referencias bibliográficas:
- Puig, A. [AMP Tech] (2017, julio 28). ¿Cómo funcionan las redes neuronales? [Archivo de video]. Recuperado de https://www.youtube.com/watch?v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Date un Vlog] (2017, abril 11) CienciaClip Challenge - ¿Qué son las redes neuronales? [Archivo de video]. https://www.youtube.com/watch?v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Deep Learning in Neural Networks: An Overview". Neural Networks. 61: 85–117. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509