Marca de clase: concepto, para qué sirve, cómo se saca, ejemplos

¿Qué es una marca de clase?
La marca de clase, también conocida como punto medio, es el valor que se encuentra en el centro de una clase, el cual representa a todos los valores que están en dicha categoría. Fundamentalmente, la marca de clase es usada para el cálculo de ciertos parámetros, como la media aritmética o la desviación estándar.
Entonces, la marca de clase es el punto medio de cualquier intervalo. Este valor también es muy útil para encontrar la varianza de un conjunto de datos ya agrupados en clases, lo que a su vez permite comprender a qué distancia del centro se encuentran esos datos determinados.
Distribución de frecuencia
Para comprender qué es una marca de clases es necesario el concepto de distribución de frecuencia. Dado un conjunto de datos, una distribución de frecuencia es una tabla que divide dichos datos en un número de categorías llamadas clases.
Dicha tabla muestra cuál es la cantidad de elementos que pertenece a cada clase; esto último se conoce como frecuencia.
En esta tabla se sacrifica parte de la información que obtenemos de los datos, ya que en vez de tener el valor individual de cada elemento, solo sabemos que pertenece a dicha clase.
Por otro lado, ganamos una mejor comprensión sobre el conjunto de datos, ya que de esta forma es más fácil apreciar patrones establecidos, lo que facilita la manipulación de dichos datos.
¿Cuántas clases considerar?
Para realizar una distribución de frecuencia primero debemos determinar la cantidad de clases que se desean tomar y elegir los límites de clase de las mismas.
La elección de cuántas clases tomar debe ser de manera conveniente, teniendo en cuenta que un número pequeño de clases puede ocultar información sobre los datos que deseamos estudiar y uno muy grande puede generar demasiados detalles que no necesariamente sean útiles.
Los factores que debemos tomar en cuenta al momento de elegir cuántas clases tomar son varios, pero entre estos destacan dos: el primero es tomar en cuenta cuántos datos tenemos que considerar; el segundo es saber de qué tamaño es el rango de la distribución (es decir, la diferencia entre la observación más grande y la más pequeña).
Después de tener las clases ya definidas procedemos a contar cuántos datos existen en cada clase. Este número es llamado frecuencia de clases y se denota por fi.
Como anteriormente habíamos dicho, tenemos que una distribución de frecuencia pierde la información que proviene de manera individual de cada dato u observación. Por ello se busca un valor que represente a toda la clase a la cual pertenezca; este valor es la marca de clases.
¿Cómo se obtiene?
La marca de clase es el valor central que representa una clase. Se obtiene al sumar los límites del intervalo y dividir este valor entre dos. Esto podríamos expresarlo matemáticamente como sigue:
xi= (Límite inferior + Límite superior)/2.
En esta expresión xi denota la marca de la i-ésima clase.
Ejemplo
Dado el siguiente conjunto de datos, dar una distribución de frecuencia representativa y conseguir la marca de clases correspondientes.

Como el dato con mayor valor numérico es 391 y el menor es de 221, tenemos que el rango es 391 -221= 170.
Elegiremos 5 clases, todas con el mismo tamaño. Una forma de elegir las clases es la siguiente:

Nótese que cada dato está en una clase, estas son disjuntas y tienen el mismo valor. Otra forma de elegir las clases es considerando a los datos como parte de una variable continua, la cual podría alcanzar cualquier valor real. En este caso podemos considerar clases de la forma:
205-245, 245-285, 285-325, 325-365, 365-405
No obstante, esta forma de agrupar los datos puede presentar ciertas ambigüedades con las fronteras. Por ejemplo, en el caso del 245 surge la pregunta: ¿a qué clase pertenece, a la primera o a la segunda?
Para evitar estas confusiones se hace una convención de puntos extremos. De esta manera, la primera clase será el intervalo (205,245], la segunda (245,285], y así sucesivamente.

Una vez definidas las clases, procedemos a calcular la frecuencia y nos queda la siguiente tabla:
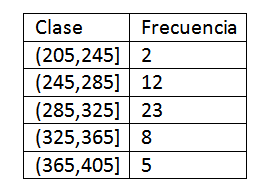
Luego de obtener la distribución de frecuencia de los datos, procedemos a encontrar las marcas de clases de cada intervalo. En efecto, tenemos que:
x1=(205+ 245)/2=225
x2=(245+ 285)/2=265
x3=(285+ 325)/2=305
x4=(325+ 365)/2=345
x5=(365+ 405)/2=385
Podemos representar esto mediante el siguiente gráfico:
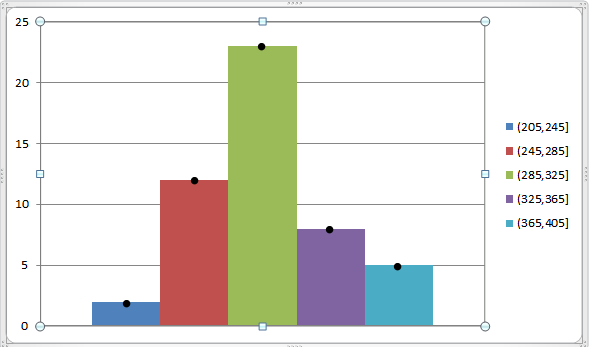
¿Para qué sirve?
La marca de clase es muy funcional para hallar la media aritmética y la varianza de un grupo de datos que ya han sido agrupados en distintas clases.
Podemos definir a la media aritmética como la suma de las observaciones obtenidas entre el tamaño de la muestra. Desde un punto de vista físico, su interpretación es como el punto de equilibrio de un conjunto de datos.
Identificar todo un conjunto de datos por un solo número puede ser riesgoso, por lo cual también hay que tomar en cuenta la diferencia entre este punto de equilibrio y los datos reales. A estos valores se les conoce como desviación de la media aritmética, y con estos se busca determinar cuánto varía la media aritmética de los datos.
La manera más común de dar con este valor es por la varianza, que es el promedio de los cuadrados de las desviaciones de la media aritmética.
Para calcular la media aritmética y la varianza de un conjunto de datos agrupados en una clase hacemos uso de las siguientes fórmulas, respectivamente:
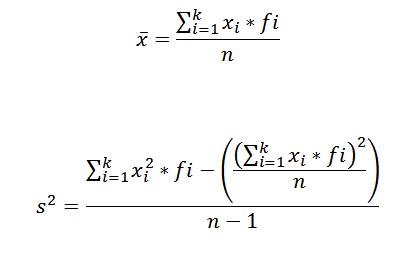
En estas expresiones xi es la i-ésima marca de clase, fi representa la frecuencia correspondiente y k el número de clases en que fueron agrupados los datos.
Ejemplo
Haciendo uso de los datos dados en el ejemplo anterior, tenemos que podemos ampliar un poco más los datos de la tabla de distribución de frecuencia. Se obtiene lo siguiente:
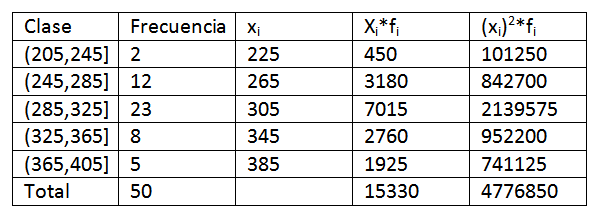
Luego, al sustituir los datos en la fórmula, nos queda que la media aritmética es:
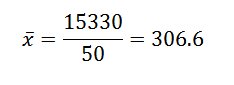
Su varianza y desviación estándar son:
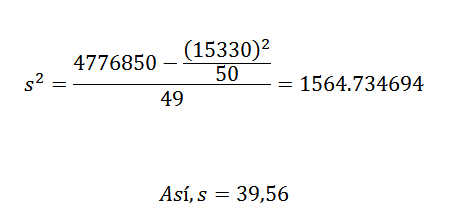
De esto podemos concluir que los datos originales tienen una media aritmética de 306,6 y una desviación estándar de 39,56.